こんにちは。モビリティサービス事業部 開発部の対馬です。
私は業務上、GPS端末とそれにかかわるWebアプリケーション開発に携わることが多いのですが、
GPS端末から送られてくるデータは、ロギングする頻度の関係でデータ量が非常に多いため、その保存方法に工夫が必要であると思わされることがしばしばあります。
そのデータ量の多さから、DBですべてを保持することが困難であるため、一部はデータファイルで保存したりもしますが、データ検索のしやすさや、データ保存時のトランザクションの容易さという観点から、やっぱりDBを使いたいと思うことがあります。
そこで、今回は、下記のようなお題で位置情報データを扱う検証をしてみようと思います。
ちなみに弊社ではデータベースとして、RDBMSのPostgreSQLを採用することが多いので、今回の検証もそれに倣ってPostgreSQLの前提で考えます。
データ量の前提
20,000端末が一日12時間ウィークデーでびっしり走るくらいの計算のデータ。
・テーブルパーティションしないとまずパフォーマンスに問題がありそう。
・テーブルパーティションしてもレコード数がかなり多いので、クエリ実行が問題なく行えるかどうか不安。
と考えて、jsonb型テーブルとパーティション(月単位テーブル)の組み合わせで試行してみます。
このパーティション単位にした理由は、
・大体、一回の検索では多くても一ヵ月単位でデータを検索することが多いこと
・大体、端末単位でデータを検索することが多いこと
のようなアプリケーションを想定しているためです。
ちなみに今回の想定データは、運行の詳細データです。
端末が急挙動や速度超過を検知した際のイベントデータとは別物で、
イベントデータの場合は複数端末の横串検索をすることが多いので、端末単位でパーティションしてしまうと不都合があります。
1.テーブル設計
以下のようなテーブルを作成
|
1 2 3 4 5 6 |
CREATE TABLE public.traffic_datas( ym integer, term_id integer, rdf_data jsonb ) |
2.データフォーマット設計
以下のようなフォーマットのデータを作成し、jsonb型のカラムに保存。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
data = [ {s_time:'2018-11-01 00:00:00', latitude:43063358, longitude:141359727}, {s_time:'2018-11-01 00:00:05', latitude:43063358, longitude:141359727}, {s_time:'2018-11-01 00:00:10', latitude:43063358, longitude:141359727}, ・ ・ ・ {s_time:'2018-11-30 20:59:55', latitude:43063358, longitude:141359727} ] insert into traffic_datas values(201811,11120262,data); |
時刻は5秒間隔。8時~20時まで連続して走行、土日は走行しない、という想定のデータ量です。
60sec * 60min * 12hour * 20day / 5sec = 172,800レコード。
※テーブルのレコードが172,800ではなく、1カラムに入ってるjson配列の数が172,800。
なのでテーブル的にはこれで1レコードです。
20,000端末なので最大20,000レコードが保存されます。
まずは普通にselectしてみます。
|
1 2 |
select ym,term_id,substring(rdf_data::TEXT,0,1000) from traffic_datas where ym=201811 and term_id=11120262 |
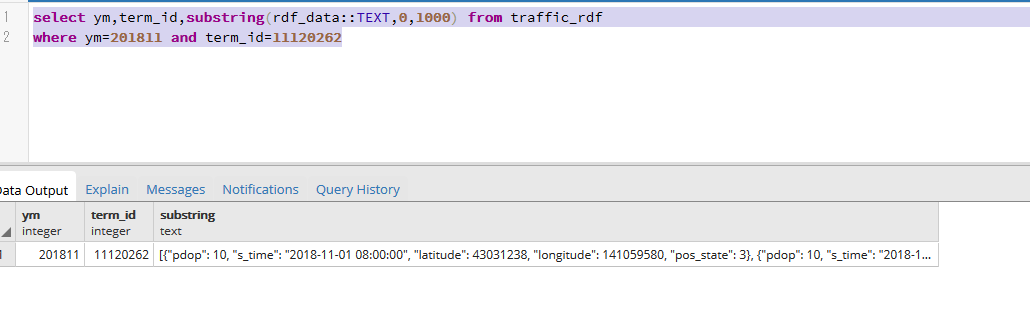
20,000レコードしかないのでindex無しでも特に問題ありません。
(データ量が多すぎるため1000文字分のテキストに変換してます)
が、ここからこのデータをどう扱えばいいのか。jsonをPHPで解析?
じゃなく、SQLで解析します。
|
1 2 3 |
SELECT * from jsonb_to_recordset( (select rdf_data from traffic_datas where term_id=11120262) ) as rdf (s_time timestamp, latitude int, longitude int, pdop int, pos_state int) where s_time between '2018-11-01 00:00:00' and '2018-11-01 23:59:59' |
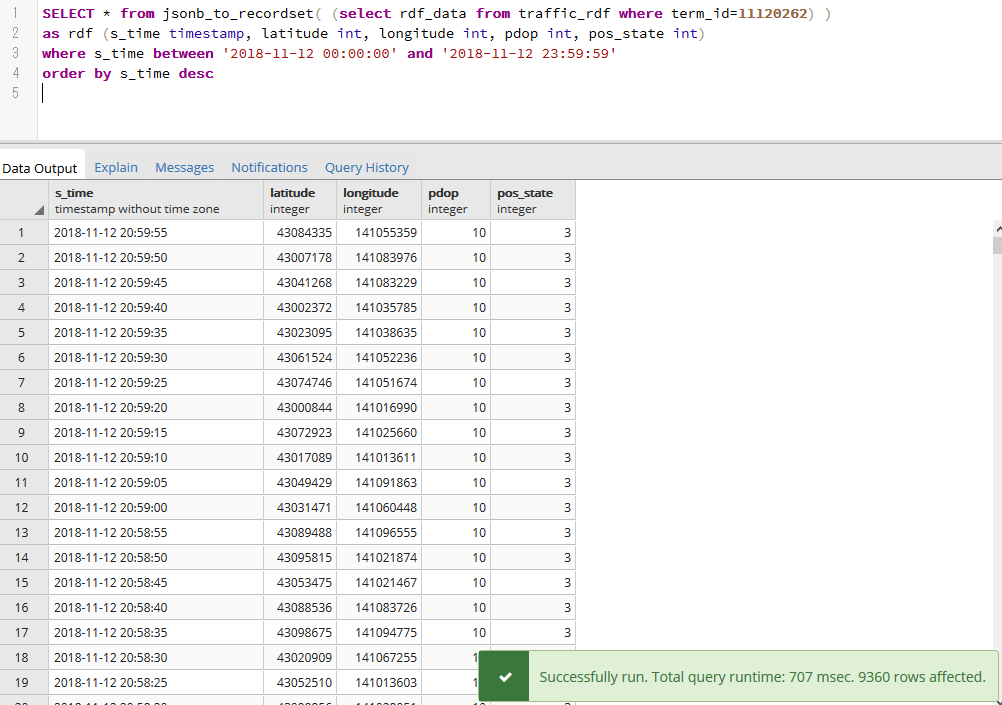
実行環境は、そこそこ早いWindowsのローカルマシン、PostgreSQLのバージョンは10.xです。
実行時間は707msecと、単純なselectクエリにしては遅いですが、同様のことを172,800 × 20,000 = 3,456,000,000(30億!) レコードが保存されるテーブルで行うよりは早い、というのが想像できると思います。
ただ、そのようなテーブルを実際に作成したうえでの速度比較については、データ容量の都合上断念しました・・・
クエリ解説
|
1 2 3 4 5 6 |
[ {k1:v1,k2:v2,k3:v3}, {k1:v1,k2:v2,k3:v3}, {k1:v1,k2:v2,k3:v3} ] |
という構造のjson配列(PHPでDBからpg_fetch_assocでデータを取得するとこんなフォーマットになりますね)をPostgreSQLのjsonb型に保存してる場合、
jsonb_to_recordsetという関数でjsonb型のカラムを取得して、k1,k2,k3に対してエイリアス的にスキーマ定義してやると、
rdf (s_time timestamp, latitude int, longitude int, pdop int, pos_state int)
というテーブルから普通にデータを取得するように扱えるようになります。
ので、order by とかwhereとか、jsonbに対して、普通のテーブルを操作するようにクエリを発行することができます。
便利ですね。
こういうことは、無理してPostgreSQLでやらなくても、もっと便利なAWSのサービスがありそうな気もしますが、敢えてPostgreSQLでやるとするとどうなるか、という観点で今回は検証してみました。
それでは、最後までご覧いただきありがとうございました。






