
こんにちは、データアナリティクス部のフバチ・ロベルトです。故郷ポーランドでは既に雪が溶け、日増しに暖かさを感じられるようになりました。以前、有機化合物の合成に携わっていた会社での経験が思い起こされます。その会社は安全を考慮して人里離れた森林に囲まれた丘陵地帯に位置しており、四季折々の風景の変化を楽しむことができました。冬は雪に覆われた裸の木々が特徴的で、春が訪れると、新緑が眼前に広がり始め、さまざまな色が混じり合います。夏になると、緑が深まり、秋には様々な色へと変わりゆく様子が、まるで絵画のようでした。
はじめに
有機合成の分野では、主な目標の一つは、既存の有機化合物をより効果的に生成する新しい方法を開発することです。また、特定の望ましい性質を持つ新しい化合物を設計することも重要です。これを達成するためには、新しい化合物の分子構造をデザインし、それに適した合成方法を開発する必要があります。
これらの目標を達成するには、多くの時間と研究チームの努力、十分な資金の支援が不可欠です。そのため、科学者や起業家は、研究を支援するための効率的なコンピュータ支援技術の開発に注力しています。近年では、人工知能(特にニューラルネットワーク)を利用して有機合成の問題を解決しようとする研究が進んでいます。このためには、化合物や反応をコンピュータが理解できる形式で記述することが求められます。例えば、SMILES(簡易分子入力線形表現システム)は、化学構造を短いASCII文字列で表現する方法として広く用いられています(図1を参照してください)。
人工知能の進歩により、ChatGPTのような大規模言語モデルが開発されました。これらのモデルは科学、金融、ソフトウェア工学など多岐にわたる分野での応用が評価されています。大規模言語モデルの登場により、研究者たちは化学プロセスの改善にこれらを活用する機会を探求しています。特にインターネットを通じて、これらのモデルは迅速に必要な情報を提供することができます。
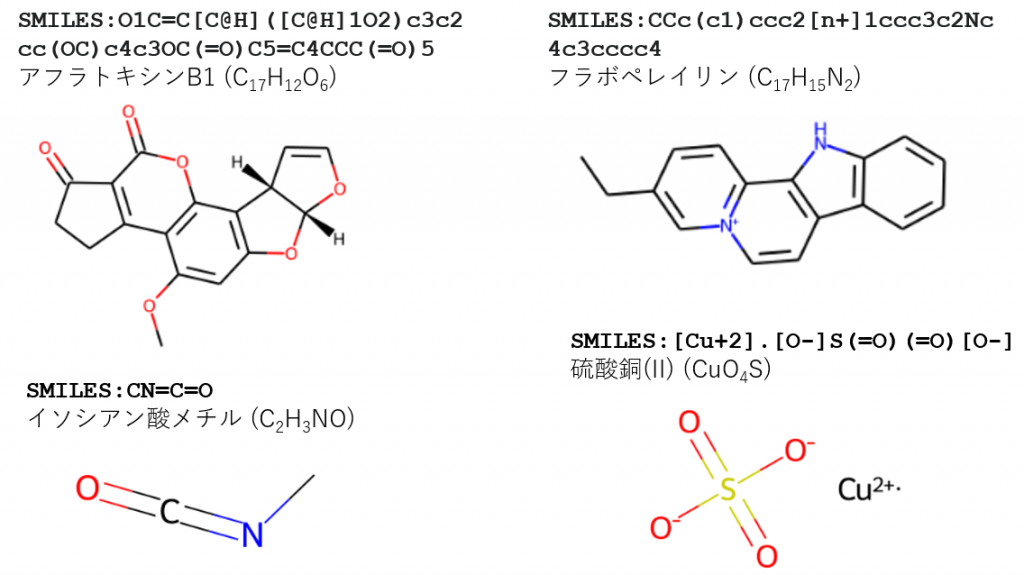
図 1. SMILESの概念のイラストレーション
LLM
Guo et al. (2023)の研究によると、化学分野のいくつかの課題で、人気のある言語モデル(GPT-4、GPT-3.5、Davinci-003、LLama、Galactica)が評価されました。この研究結果から、これらのモデルは分子のSMILES文字列を深く理解する必要がある課題(例えば、反応予測、合成計画、化合物名の予測など)には向いていないことがわかりました。しかし、反応収率の予測や試薬の選択といった課題では比較的良い成果を示しています。また、この研究でGuoらが導入した新しいプロンプトテンプレートが注目されており、これはDong et al. (2023)の研究で提案された文脈内学習アプローチに基づいており、図2に示されています。

図2.「化学反応予測」のためのプロンプトの例が示されています(Yu et al., 2024)。このプロンプトは、Guo et al. (2023)が提案したテンプレートに基づいて作られています。このテンプレートは5つの部分から成り立っており、中でも特に重要なのが「文脈内学習(ICL)」です。文脈内学習部分には、タスクをどのように進めるかを示す具体的な例が含まれています。
表1. 化学合成における LLM アプリケーションへのアプローチの例

有機合成における特定の課題、例えば分子のSMILES表記の理解において、大規模言語モデル(LLM)が直面する問題は、研究者たちがより良い成果を達成するための新しいアプローチを探るきっかけとなりました。表1では、そのような取り組みの例が示されており、これには大規模言語モデルのファインチューニング、インターネットや文献の検索、化学専門のツールの使用といった潜在的な解決策が含まれています。これらの解決策は、化学の分野に特化しているものの、他の分野での大規模言語モデルの適用にも手法として応用可能であることを理解することが重要です。
LlaSMol
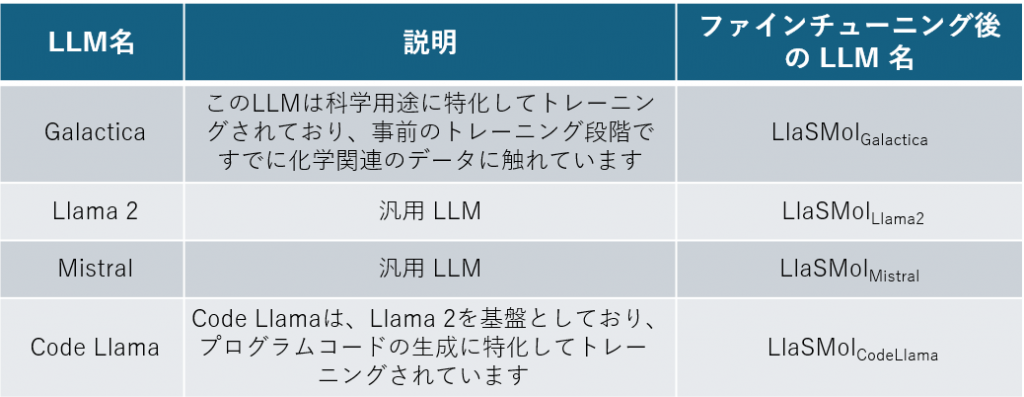
Yu et al.(2024年)による研究では、大規模言語モデル(LLM)のファミリーである「LlaSMol」(Large language models on small molecules)が開発されました。これは、既存のLLM(表2を参照してください)を化学タスクに特化するよう微調整(ファインチューニング)したものです。この微調整のために、新しい大規模なファインチューニングデータセット「SMolInstruct」が作成されました。SMolInstructには合計14の化学タスクが含まれており、これらは以下の4つのカテゴリーに分類されています(図3も参照してください):
1. 名前変換:化合物の名前からSMILES表記を見つけること。
2. 分子の説明:分子についての説明を提供するか、説明に基づいて分子を提案すること。
3. 分子の性質予測:与えられた分子の性質を予測すること。
4. 化学反応の計画:基質から反応生成物を予測するか、特定の生成物を得るために必要な基質を提案すること。
表2.化学タスクに特化するようファインチューニングされたLLM (LlaSMolモデル)
Yu et al.(2024年)による実験では、LlaSMolモデルが、特定のタスクにおいて最先端の他のモデル(非LLMベース)と同等の性能を発揮することが示されました。また、ファインチューニングされていないLLMに比べても、LlaSMolはより優れた性能を示しました。特に注目すべきは、LlaSMolモデルの性能が、ファインチューニングに用いられたLLMの種類に大きく依存していることが明らかになった点です。たとえば、プログラミング言語に関する知識を持つCodeLlamaを基にしたLlaSMolCodeLlamaは、LlaSMolLlama2よりも顕著に優れた性能を示しています。この差は、CodeLlamaのプログラミング言語の知識が、分子表現のためのコーディング言語であるSMILESとの相乗効果を生んでいるとYu et al.は指摘しています。また、LlaSMolGalacticaが他のモデルより優れている理由は、Galacticaが化学関連の文献で事前にトレーニングされていたためです。

図3.大規模言語モデル(LLM)が行うことができる最も基本的なタスクの一つである名前変換を示しています。この図では、SMolInstructデータセットから選ばれた名前変換タスクの例を用いて、この問題を解説しています。データセットで提供される正解とともに、図ではGPT-4(ファインチューニングなし)を使用して得られた回答も掲載されています。例示されているケースでは、化合物名ではなくSMILES表記を扱う必要があり、GPT-4は正確な回答を提供できていませんでした。しかし、インターネットの情報を活用することで、GPT-4の結果は改善されることが示されています。
Coscientist
最近の研究動向には、様々な物質の取得プロセスを完全に自動化する試みに対する関心が高まっています。これらの取り組みの目標は、合成ルートの計画や新しい分子の開発の段階だけでなく、生産プロセスや実験の実行においても人間の介入を排除することです。例えば、ロボットによって行われる実験はより厳密に制御され、得られる結果は再現性が高く解釈もしやすくなります。このアプローチの一例が、Coscientistプロジェクト(Boiko et al.、2023)で示されています。
Coscientistモデルは、以下のような主要なタスクを実行できます:
1. インターネット上のデータを利用して化合物の化学合成を計画する。
2. 以前に収集された実験データを分析し、合成を最適化する。
3. 幅広いハードウェアに関する文書を検索する。
4. クラウドベースのラボでコマンドを実行するための文書を使用する。
5. 複雑な科学的タスクを実行する(様々なハードウェアモジュールを同時に使用し、多様なデータソースを統合する)。
Coscientistの核となるのは、GPT-4を基にしたチャットプランナーで、これがアシスタントとして機能します。このプランナーは人間のユーザーからの指示を受け取り、ウェブ検索や文書検索、コード実行、自動化モジュールを制御します。ウェブ検索と文書検索は、インターネットや文書から情報を収集するために別のLLM(例:search-gpt-4)を使用します。一方、自動化モジュールは、ロボットなどの物理的なハードウェアと通信するために用いられます。これらのタスクは、ReActやChain of Thought、Tree of Thoughtsなどの高度なプロンプティング戦略を活用して実行されますが、ユーザーからCoscientistへの入力は「複数のスズキ反応を実行する」といった単純なテキストプロンプトでも十分です(Boiko et al.、2023)。
ChemCrow
ChemCrow(Bran et al.、2023)は、有機合成、薬物開発、材料発見などの分野におけるタスク向けに設計された大規模言語モデル(LLM)ベースのエージェントです。このモデルの性能は、WebSearch、Name2SMILES、ReactionPlanner、ControlledChemicalCheckなど、18種類の専門家が設計した化学ツールを統合することで向上しています。開発チームは、実験中にOpenAIのGPT-4をLangChainフレームワークとともに使用しました。
Coscientistプロジェクトと同様に、ChemCrowも物理的な世界との対話と自律的な実験を行うことを目指しています。この目標を達成するために、Bran et al.(2023)はクラウド接続を備えたロボティック合成プラットフォームへの接続について研究を行いました。また、論文ではChemCrowによって成功裏に行われたいくつかの化学合成の例が紹介されています。
まとめ
大規模言語モデル(LLM)を化学合成に使用することは、大いに有望であると考えられています。ただし、これらのモデルは化学のアプリケーションに合わせて適応させる必要があります。この適応は、モデルのファインチューニングや、インターネットおよび文献へのアクセスの向上、または専門家が設計したツールの活用を通じて達成することが可能です。
将来的には、大規模言語モデルが有機合成の計画過程を大幅に改善すると期待されています。これにより、実験や生産の過程をより効率的に、かつ独立して監視する能力を持つことができるようになるでしょう。
文献
論文:
Boiko D. A., MacKnight R., Kline B., Gomes G. (2023): Autonomous chemical research with large language models, Nature, Vol 624, 21/28 December 2023
Bran A. M., Cox S., Schilter O., Baldassari C., White A. D., Schwaller Ph. (2023): Augmenting large language models with chemistry tools, arXiv:2304.05376v5
Dong Q., Li L., Dai D., Zheng C., Wu Zh., Chang B., Sun X., Xu J., Li L., and Sui Zh. (2023): A survey on in-context learning, arXiv:2301.00234
Guo T., Guo K., Nan B., Liang Zh., Guo Zh., Chawla N. V., Wiest O., Zhang X. (2023): What can Large Language Models do in chemistry? A comprehensive benchmark on eight tasks, arXiv:2305.18365v3
Yu B., Baker F. N., Chen Z., Ning X., Sun H. (2024): LlaSMol: Advancing Large Language Models for Chemistry with a Large-Scale, Comprehensive, High-Quality Instruction Tuning Dataset, arXiv:2402.09391v2
ウェブサイト:
ChemCrow: https://github.com/ur-whitelab/chemcrow-public
Coscientist: https://github.com/gomesgroup/coscientist/blob/main/synthesis_capabilities/labels.csv
LlaSMol: https://github.com/OSU-NLP-Group/LLM4Chem
RDKiT: https://www.rdkit.org/docs/index.html



