こんにちは、基盤整備グループの上西です。
AWSのGlue Crawlersでクローラーを実行する際にCSVファイルのままだと、date型にしたいデータがstringデータのままであったり、ダブルクォーテーションで囲った文字列がスペースで切れて隣のカラムのデータを上書きしてしまうなどの不都合が生じることがあるため、CSVファイルをParquetファイルとして出力したいことがありました。
ParquetファイルはCSVファイルに比べて容量が小さくカラム毎に型を定義することができるので、Glueデータカタログでデータベースとして扱いやすい特徴があります。
クローラー実行後にGlueのデータカタログからスキーマの編集でdate型にキャストするという方法もありますが、後述する今回の要件に適合しないためGlue ETL jobsを使用する方法にしました。
問題の確認
S3に保存しているCSVのファイルだがこんな”MM/dd/yyyy”の形式のため、このままクローラーを実行するとString型のままであり、データカタログからスキーマを編集してdate型にしてもキャストできずにデータがnullになってしまう。
| servicePeriodStartDate |
| 11/21/2023 |
| 11/21/2023 |
| 11/21/2023 |
Glue ETL jobs の作成
上記の問題の解決のため、Glue ETL jobsを使用してデータに対して前処理を行いdate型にキャストします。
ETL jobsのvisual ETLを使用すると、視覚的にETLを組み立てることができます。今回はSourcesにCSVデータが保存されているS3バケットを選択し、TransformsにはChange Schemaを選択して、TargetsにはS3を選択しました。これによりS3からCSVを取り出しててスキーマの編集をして、CSVから変換したParquetファイルをS3に保存することができます。
※GlueからS3を参照させるために以下の様なポリシーが付与されたIAMロールを用意する必要があります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": [ "s3:PutObject", "s3:GetObject" ], "Resource": "対象のS3バケット" } ] } |
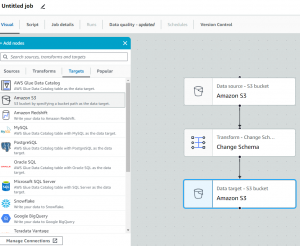
ETL jobsの詳細設定は省略しますがvisualを組み立てると以下の様なscriptが生成されます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
import sys from awsglue.transforms import * from awsglue.utils import getResolvedOptions from pyspark.context import SparkContext from awsglue.context import GlueContext from awsglue.job import Job args = getResolvedOptions(sys.argv, ["JOB_NAME"]) sc = SparkContext() glueContext = GlueContext(sc) spark = glueContext.spark_session job = Job(glueContext) job.init(args["JOB_NAME"], args) # Script generated for node Amazon S3 AmazonS3_node123456789 = glueContext.create_dynamic_frame.from_options( format_options={"quoteChar": '"', "withHeader": True, "separator": ","}, connection_type="s3", format="csv", connection_options={ "paths": ["s3://hogehoge/hogehoge/"], "recurse": True, }, transformation_ctx="AmazonS3_node123456789", ) # Script generated for node Change Schema ChangeSchema_node987654321 = ApplyMapping.apply( frame=AmazonS3_node123456789, mappings=[ ("servicePeriodStartDate", "string", "date", "string"), #~略~ ], transformation_ctx="ChangeSchema_node987654321", ) # Script generated for node Amazon S3 AmazonS3_node234567 = glueContext.write_dynamic_frame.from_options( frame=ChangeSchema_node987654321, connection_type="s3", format="glueparquet", connection_options={ "path": "s3://hogehoge/hogehoge/", "partitionKeys": [], }, format_options={"compression": "snappy"}, transformation_ctx="AmazonS3_node234567", ) job.commit() |
このまま実行しても”MM/dd/yyyy”の日付データはdate型にキャストされなく、ただのParquetファイルが指定したS3バケットに保存されるだけなので、生成されたscriptに対して編集が必要です。
scriptの編集
今回の要件としてservicePeriodStartDateカラムのデータをstring型からdate型に変えたいが対応する日付の形式ではないため、スキーマの編集前に”MM/dd/yyyy”から”yyyy/MM/dd”に変えてdate型へキャストします。
編集箇所は以下の通りです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# 必要なモジュールと関数をインポート from awsglue.dynamicframe import DynamicFrame from pyspark.sql.functions import to_date, col # Script generated for node Amazon S3 AmazonS3_node123456789 = glueContext.create_dynamic_frame.from_options( # ~略~ # "列の日付形式を"MM/dd/yyyy"から"yyyy/MM/dd"に変換 df = AmazonS3_node1234567.toDF() df = df.withColumn("serviceperiodstartdate", to_date(col("serviceperiodstartdate"), "MM/dd/yyyy")) # 変換したDataFrameをDynamicFrameに戻します AmazonS3_node1234567 = DynamicFrame.fromDF(df, glueContext, "AmazonS3_node1234567") # Script generated for node Change Schema # ~略~ |
解説
GlueのDataFrameとDynamicFrameについて
DataFrame
DataFrame はテーブルと似ており、機能スタイル (マップ/リデュース/フィルター/その他) 操作と SQL 操作 (選択、プロジェクト、集計) をサポートしています。
AWSドキュメントDynamicFrameクラスの説明より引用。
DynamicFrame
DynamicFrame は、DataFrame と似ていますが、各レコードが自己記述できるため、最初はスキーマは必要ありません。代わりに、AWS Glue は必要に応じてオンザフライでスキーマを計算し、選択 (または共用) タイプを使用してスキーマの不一致を明示的にエンコードします。これらの不整合を解決して、固定スキーマを必要とするデータストアとデータセットを互換性のあるものにできます。
AWSドキュメントDynamicFrameクラスの説明より引用。
要約するとデータの抽出、変換、ロード(ETL)操作において、自己記述型(データ構造やオブジェクトが自身の構造や特性を記述できる)の特性を持つことで柔軟性があり、スキーマの制約を緩和するための便利なツールです。
DynamicFrameはETL処理に強く、DataFrameはテーブル処理に強い。これらの特性を生かして、データ⼊出⼒とそれに伴うETL処理はDynamicFrameで⾏い、テーブル操作はDataFrameで⾏う。DynamicFrameをDataFrameに変換するのがtoDF関数で、DataFrameをDynamicFrameに変換するのがfromDFです。
今回の例だとDynamicFrameでS3からデータを取得(ETL処理)し、toDF関数でDataFrameに変換した後SQL操作のto_dateで日付の型を変換して、DynamicFrameに戻しています。
これらの処理を経てCSVからParquetファイルに変換することで、Glueのクローラでクローリングした際に正しい表記のdate型に変換されたデータカタログが生成できます。
まとめ
date型にキャストする際に日付の表記が独自の形式でなければ通常はGlueのCSVファイルのクローリングだけで済みますが、今回の様なケースですとGlueのETL jobsが有効だと感じました。予備知識としてPythonのPandasやApache Sparkでデータ処理をした経験がある方でないと学習コストがかかるかもといった懸念も感じました。今回、実際にGlue ETL jobsを使用するにあたり、参考文献にも挙げている”AWS Glue ETLパフォーマンス・チューニング①基礎知識編”の資料がとても参考になりました。ブラックベルトのセミナーがYouTubeにあったので参考に共有しておきます。
参考文献
DevelopersIO Glueデータカタログ経由でCSVを読み込んで日付型にキャストする方法
Qiita AWS Glue の DynamicFrame とは?
AWS Glue Scala DynamicFrame クラス
AWS Glue ETLパフォーマンス・チューニング①基礎知識編






